data.wu.ac.at
Open Data and ongoing activities at
Institute for Information Business
at WU Vienna

The project intends to research and develop novel automated and community-driven data quality improvement techniques and then integrate pilot implementations into existing Open Data portals.
The goal of the project is to enhance usability of Open Data and to enhance its accessibility for non-expert users.
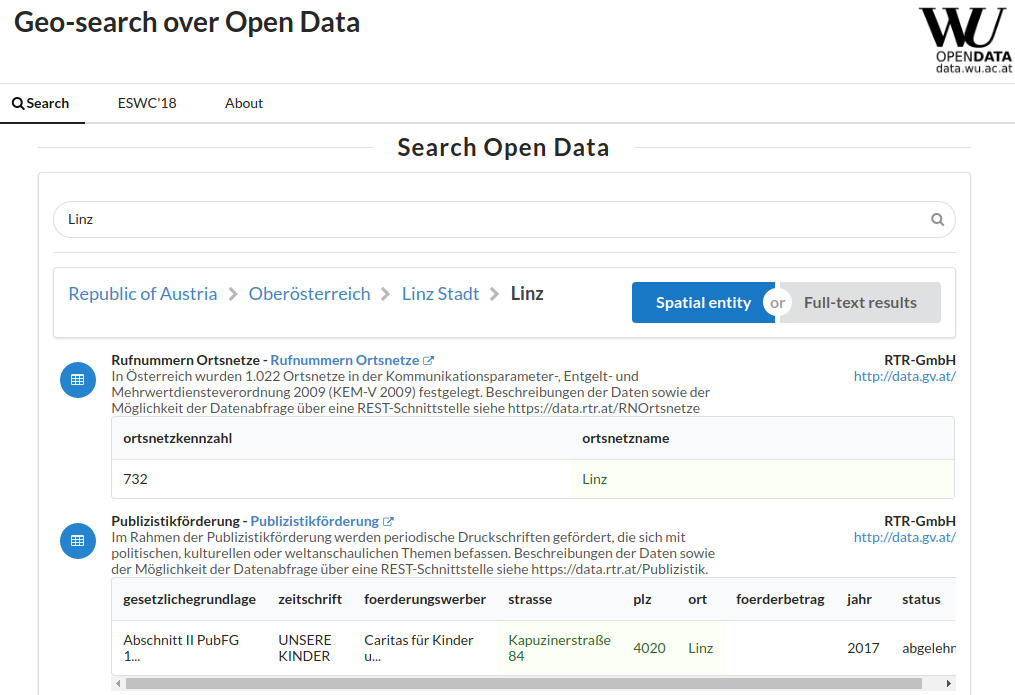
Intuitively, most datasets found on governmental Open Data portals are organized by spatio-temporal criteria, that is, single datasets provide data for a certain region, valid for a certain time period. Likewise, for many use cases (such as, for instance, data journalism and fact checking) a pre-dominant need is to scope down the relevant datasets to a particular period or region. Rich spatio-temporal annotations are therefore a crucial need to enable semantic search for (and across) Open Data portals along those dimensions, yet – to the best of our knowledge – no working solution exists. To this end, we (i) present a scalable approach to construct a spatio-temporal knowledge graph that hierarchically structures geographical as well as temporal entities, (ii) annotate a large corpus of tabular datasets from open data portals with entities from this knowledge graph, and (iii) enable structured, spatio-temporal search and querying over Open Data catalogs, both via a search interface as well as via a SPARQL endpoint, available at data.wu.ac.at/odgraphsearch/.
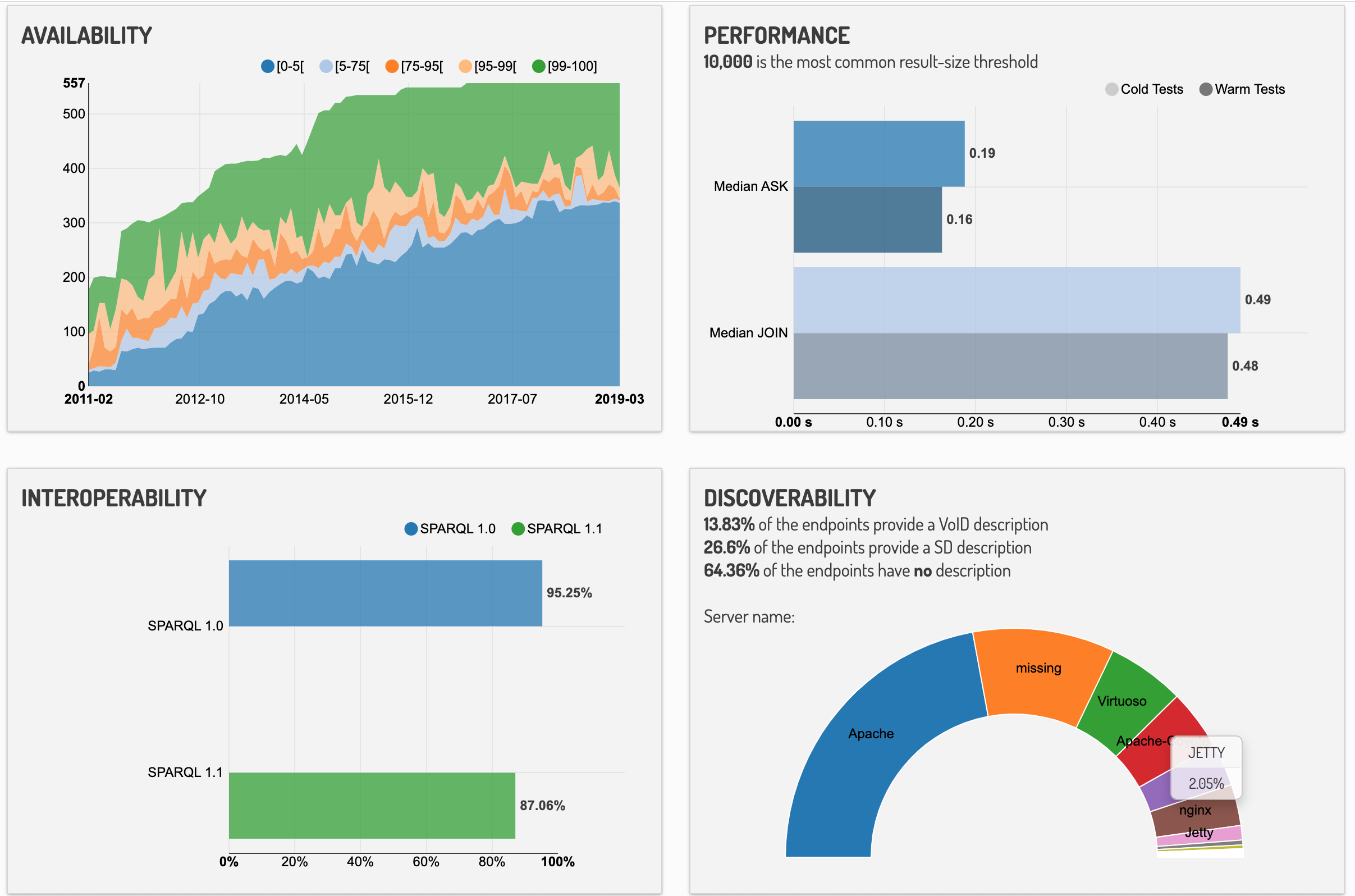
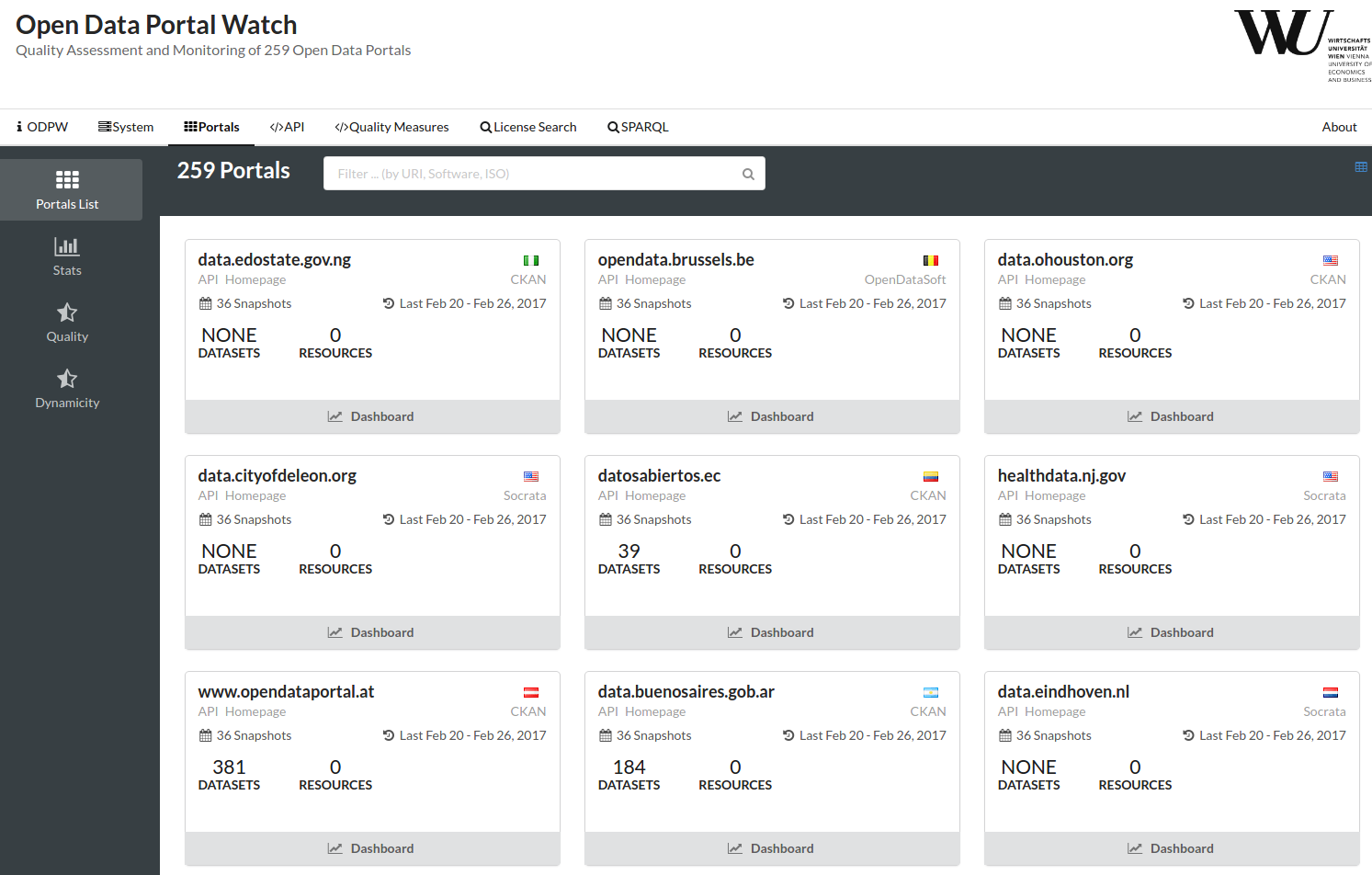
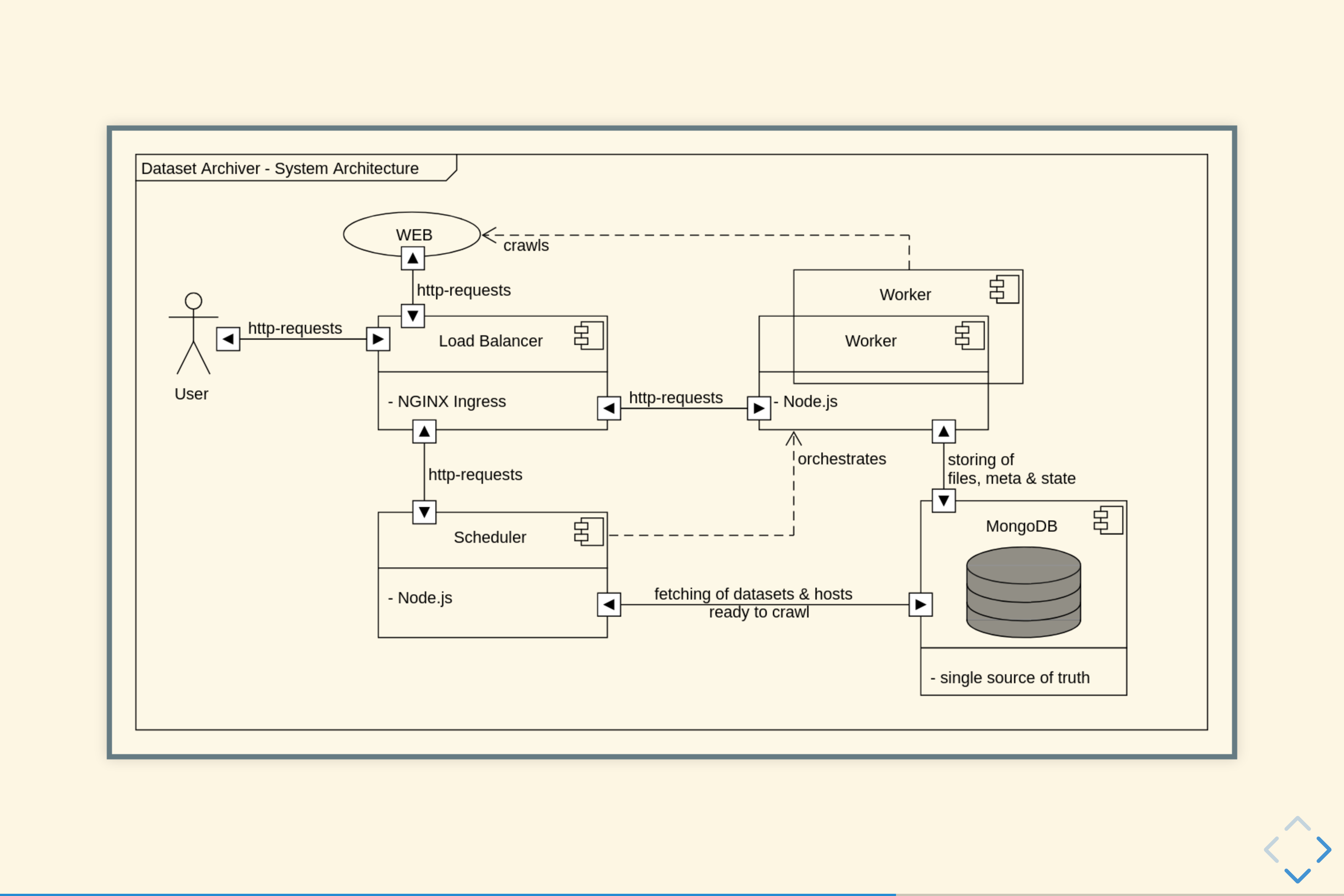
The Open Data movement has become a driver for publicly available data on the Web. More and more data - from governments, public institutions but also from the private sector - is made available online and is mainly published in so called Open Data portals. However, with the increasing number of published resources, there are a number of concerns with regards to the quality of the data sources and the corresponding metadata, which compromise the searchability, discoverability and usability of resources. In order to get a more complete picture of the severity of these issues, the present work aims at developing a generic metadata quality assessment framework for various Open Data portals: we treat data portals independently from the portal software frameworks by mapping the specific metadata of three widely used portal software frameworks (CKAN, Socrata, OpenDataSoft) to the standardized DCAT metadata schema. We subsequently define several quality metrics, which can be evaluated automatically and in a efficient manner. Finally, we report findings based on monitoring a set of over 260 Open Data portals with 1.1M datasets. This includes the discussion of general quality issues, e.g. the retrievability of data, and the analysis of our specific quality metrics.
DBpedia crystallized most of the concepts of the Semantic Web using simple mappings to convert Wikipedia articles (i.e., infoboxes and tables) to RDF data. This “semantic view” of wiki content has rapidly become the focal point of the Linked Open Data cloud, but its impact on the original Wikipedia source is limited. In particular, little attention has been paid to the benefits that the semantic infrastructure can bring to maintain the wiki content, for instance to ensure that the effects of a wiki edit are consistent across infoboxes. In this paper, we present an approach to allow ontology-based updates of wiki content. Starting from DBpedia-like mappings converting infoboxes to a fragment of OWL2 RL ontology, we discuss various issues associated with translating SPARQL updates on top of semantic data to the underlying Wiki content. On the one hand, we provide a formalization of DBpedia as an Ontology-Based Data Management framework and study its computational properties. On the other hand, we provide a novel approach to the inherently intractable update translation problem, leveraging the pre-existent data for disambiguating updates.
There is a growing body of literature recognizing the benefits of Open Data. However, many potential data providers are unwilling to publish their data and at the same time, data users are often faced with difficulties when attempting to use Open Data in practice. Despite various barriers in using and publishing Open Data still being present, studies which systematically collect and assess these barriers are rare. Based on this observation we present a review on prior literature on barriers and the results of an empirical study aimed at assessing both the users’ and publishers’ views on obstacles regarding Open Data adoption. We collected data with an online survey in Austria and internationally. Using a sample of 183 participants, we draw conclusions about the relative importance of the barriers reported in the literature. In comparison to a previous conference paper presented at the conference for E-Democracy and Open Government, this article includes new additional data from participants outside Austria, reports new analyses, and substantially extends the discussion of results and of possible strategies for the mitigation of Open Data barriers.